I’ve had this book on my (digital) shelf for a long time. It’s an intimidating tome. It’s big and broad. However, it’s not exactly what I was expecting. As the book title explains, the main focus is data analysis. Not necessarily statistical or data mining analysis. Instead, chapters one through eleven are focused on plotting, mathematical analysis, and basic statistics. There’s good material but it felt scattered and slapped together.
[table]
,
Get this book if…, You want a broad survey of data analysis.
Don’t get this book if…, You’re looking for an introductory text
[/table]
My Takeaways
Nuggets of Wisdom: The book doesn’t cover any one topic with much depth. The tail end of the book rapidly goes through different machine learning / predictive analytics techniques. However, there are plenty of nuggets of wisdom you can pick up if you’re willing to page through.
- Scatter Plot Matrix (SPLOM) is a useful method of visualizing many variables at once. Plus it’s the name of the R function (in the lattice package) too!
- biplot is a function in R that helps you interpret the principal components. I didn’t realize those plots were so simple!
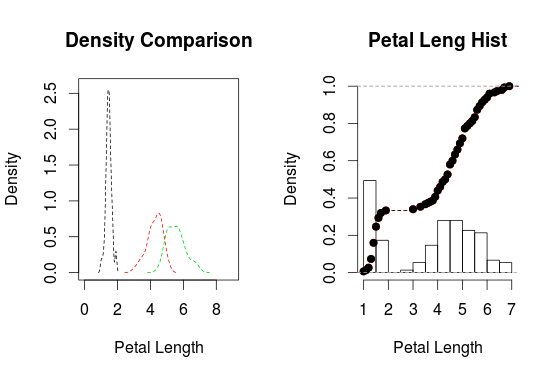
CDF and Density Plots are Really Useful: Something I don’t use often enough are density plots. It’s really useful to see how dense each class is for each variable. In addition, the Cumulative Distribution Function (CDF) is cool to show the long-tail of your data.
Strong Opinions on BI / Reporting: I really appreciated Janert’s discussion on reporting and how it’s important to understand what you’re reporting on rather than just using out-of-the-box solutions. There was a long list of Do’s and Don’ts that could have been made better by offering a framework for BI / reporting.
- I especially liked his comparison of reporting and BI as part of an “Infrastructure” mentality. Because it’s so closely tied to the database structure, there’s hesitance to change anything in reports / input to reports.
Sort of Right on Hadoop: There was a small comment on Hadoop which sort of showed the age of the book. While it was published in 2010, Janert didn’t expect Hadoop to be much of a stir due to the cost of maintaining the networks for Hadoop. What hadn’t happened yet was the rise in cloud computing. While we’ve moved on from Hadoop, it still has had a lasting impact.
- Also, Janert said that he didn’t think a core task like Matrix Multiplication could be managed well in Hadoop. Too much to keep track of. However, matrix multiplication is considered to be “stupidly parallelizable”.
Guesstimation: I liked his section on guesstimating and how models are estimates of the real world. I appreciate the emphasis on knowing the numbers and being able to get a quick estimate of what the numbers should be. Definitely an undervalued skill.
Bottom Line: I would not pick up this book as a first time reader. Nor would I pick this book up to learn more about analysis or data mining.